AIデータ時代のネットワークとセキュリティについて
SoftBank AI部Advent Calendar 20199日目の記事です! Junya(@akatsubakij)と言います。
Software DesignのイベントでAI部創設者(@kmotohas)さんに「書きましょう!」と言われ、折角の機会と思い執筆することにしました。
私について簡単にプロフィールを。
- 2019年度新卒入社。宮城県仙台市にある某大学の情報工学修士を取得。
- 現在は基地局構築業務で扱うWebアプリケーションを作りつつ、本部内でKaggle勉強会などに参画
- 10月のSB AIハッカソンで準優勝(Advent Calendar発案者のコミさんがいたらしいです)
大学院ではヘルスケア領域をターゲットとしたネットワークの応用研究をやっていました。セキュリテイもまぁそこそこ詳しい方です。 本記事では、自身の専門や現在の業務領域と絡めつつ
『AI時代やデータ時代におけるネットワーク・セキュリティとの向き合い方』
を綴っていこう思います。
【前置き】浅はかな知識のもとに綴っていきますので御了承ください
Communication Infrastructure on the Life
そもそも大学で情報通信の基礎って今習うのでしょうか?TCP/IPや情報通信理論(シャノン・ハートレーの定理)とか。このご時世そんなの知らなくてもスマホ繋がるし!という感じでしょうが、私達のインターネット時代を支える大事な分野です。興味ある人はマスタリングTCP/IPを読んでみてください。
ネットワークと聞いて最近の人が興味湧くのはIoTかなと個人的に思います。計算機小型化によってRaspberry Piなどが登場してからは、すっかりIoTという言葉が世間に定着しました。 ネットワーク分野ではよくエッジネットワークと呼ばれていたりします。クラウドコンピューティングの「データを吸い上げて中央集権的に処理する」という考えに反して、「末端のデバイスの計算機リソースも活用しよう」という考えから生まれたものです(フォグコンピューティングというクラウド、エッジの中間に位置するレイヤーもありますが今回は割愛します)。
また、ネットワークの話をする時に外せないのがセキュリティです。こちらも大学学部の講義であまり見かけることが無い?印象です。 私は研究室時代にenPiTと呼ばれる、文科省の高度情報人材育成プロジェクトに関わらせていただきセキュリティの知見を広げました。「セキュリティってハッキングとか勉強するんでしょ!」という偏見がありましたが、それはあくまでネットワークセキュリティの一分野であり、ほとんどはデータに関する法制度、プライバシー情報の扱いなど 安全な情報化社会を築いていくためには という話題の方が個人的には多い印象でした。法律の話って結構体力がいるので、意欲のある人はぜひ門戸を叩いてみてください。
AI and Network
AI部向けの記事ということで、AIとネットワークの関連性について触れたいと思います。
まずは2020年商用開始と宣言されている5G。研究界隈ではAIの積極的な活用が進んでいます。 Yaoらの研究では、5Gを構成する重要な3要素のMassive MIMO、超ミリ波技術、超高密度ネットワークをDeep Learningにより最適化しようとする記述があります。
(2019 IEEE Communications Magazineという情報通信系のトップジャーナルへ採録)
ネットワークの研究で一番注力されるのは「ネットワークリソースを有効活用する」ことです。Twitterしか閲覧していないのにAmazon Prime Video並みにネットワークを圧迫していたら、社会インフラとしてパンクしてしまいます。QoSというキーワードをベースに、これまでいくつもの最適化研究が行われてきましたが、DNN(Deep Neural Network)の登場により、その最適化機構へ機械学習を活用していく動きが出てきています。特に無線ネットワークであれば、電波の衝突やシグナルの最適化を、時系列に強いであろうRNNを活用可能という見解もあります。
また、高密度ネットワーク(ultra dense networkと言います)もAIの技術を掛け合わせればもっと良いものになります。高密度ネットワークは、いわゆるイベント会場のような無線電波が密集したような空間です。自分も研究でそのような環境を再現していましたが、電波干渉がひどくパケットロスも大きいです。IoT環境では端末数が増大するので、こうした懸念点を解消する必要があります。解決方法としては様々ですが、ネットワーク全体でスケジューリングアルゴリズムを適用したり、Deep LearningとBeamforming(特定箇所での電波受信強度が最大化するような技術)で電力効率を最大化したりするのがここ数年の動向だなと個人的に捉えています。
一方で、ネットワークへのAI適用はまだまだ課題があります。 1つ目、まずどの文献でも出てくるのが「セキュリティとプライバシー」です。ネットワークは私達の生活を支えています。チャネルのハイジャックもそうですが、AI時代で恐れているのは、意図しない学習やデータを与えることです。もしAIがそのような攻撃をされてしまえば、セル(無線ネットワークの最小単位)を乗っ取ることも可能です。私達は、AIが最適化するようデータを与えつつ、AIが誤った方向に学習しないよう制御しなくてはいけません。セキュリティの話は次節でまた詳しく述べます。
2つ目、エッジAIの可能性です。最初に述べた末端デバイスでいかにAIを適用していくかです。スマートフォンはだいぶ進化したものの、IoTデバイスはまだまだ計算機リソースが貧弱です。半永久的に動作し続ける未来はまだまだ先でしょう。とは言え全てのデータをクラウドに集中させるのは、レイテンシと汎化性能という面では適していないと考えています。データの処理フローへどのようにAIを活用化させるかは、今後も課題となっていくでしょう。
3つ目、AIはあまり関係ないですが標準化という問題です。皆さん、Raspberry PiとiPhone、Arduinoを繋げてみてくださいと言ったら、Wi-Fiルータ経由しか今は思いつかないでしょう(他の方法が思いついたあなたは天才です!!)。今は、何かしらの端末がゲートウェイ的役割を果たす必要がありますが、今後様々なデバイスを柔軟に直接的に接続していくプロトコルも必要ではないかと考えています。iPhoneのAirDropなんかは独自規格ですが、クラウド経由せずiPhoneでダイレクトにやり取りをする規格です。このようなプロトコルがIoT界隈に出てくると、世界はグッと変わるのではないかと思います。
AI and Security
以前、米国Open AIでパンダの画像にノイズを加えるとテナガザルとして判定されるという話が話題になりました。(ルパンみたい!)
もう一つ興味深い研究で、AI学習に対するポイズニング攻撃があります。 ポイズニング攻撃とは、その名の通りポイズン=毒を仕込むことで、意図しない動作を狙う典型的な攻撃手法です。
DNSキャッシュポイズニンングという攻撃手法をちょっと紹介します。皆さんは普段、google.com のようにURLを踏んでサイトに飛ぶわけですが、ネットワークでは 1.2.3.4 みたいにIPアドレスに変換をかけます。これがDNSの仕組みですが、普通はこれをDNSサーバを経由してIPを取得します。しかし、毎度のようにDNSサーバへ問合せをかけるとサーバに負荷がかかるので、DNSキャッシュサーバを用意しておきます。こうすると、中のネットワークからインターネットに出る時に、キャッシュが残っているので瞬時に名前解決でき期待通りのサイトへアクセスできます。DNSキャッシュポイズニングでは、このキャッシュサーバへ攻撃を仕掛けることで、ユーザが定期的に踏みにいくようなIPアドレスを悪意あるサイトへ誘導しようとする攻撃です。
この文献では、機械学習でも同じようなポイズニング攻撃ができることを述べています。 簡単に要約すると、学習モデルを認知しているという前提で、そのモデルが学習していく過程で特定のデータのみ間違ったラベル付けをするように学習を誘導していくという手法です。他のデータの学習精度をなるべく下げることなく実現可能です。2018年に出たものですが、DeepFakeなども話題になっていますし、日本語記事も増えていきます。詳しい解説をみたい方はそちらを(ここで数式解説とかすると長くなるので割愛)。
今後、AI社会やデータ社会が浸透してくるにあたり、考えるべき課題は以下であると私自身も考えています。
1つ目は、データの信頼性です。実はこれネットワークと非常に関わってくる部分があると考えています。「いつ、どこから来たデータか」を今後見極めていかないと、学習が全てのデータに対応しようとしmalliciouswareを仕込まれてしまいます。IoT環境整備してデータ集めてオンライン学習(逐次学習)やろうとしても、その環境内に脅威なノードを仕込まれた場合、学習が気づかぬうちに悪い方向へ収束していくかもしれません。
2つ目は、プライバシです。AIが進化しようと、データ○○時代が来ようと、人間という存在は生き残り続けます。AさんがTwitterで裏垢を使っていたとすると、AIの技術が進化して本来秘匿化したいはずのAさんの裏垢が、Aさんの属するコミュニティに暴露されたらどうでしょう。それくらい、データ相関を見るのはコンピュータは得意ですし、Aさんのそうした情報は守っていかなければなりません。AI部 Slackでも話題になっていたので言及しますが、データの譲渡・売買に関してはこれからも課題になっていくでしょう。悪意ある人間は、常にその瞬間を狙っています。近年ではNTT研究所が暗号化情報でも深層学習可能なモデルを開発したということで話題になりました。データを秘匿化しつつ、AIも最適化していくというのは継続課題になっていくと思われます。 人を中心とした社会というテーマはより一層重要になっていくでしょう。
https://www.ntt.co.jp/news2019/1909/190902a.htmlwww.ntt.co.jp
Conclusion
拙い文章でしたが、ネットワークとセキュリティに関わってきた自分が、「これからはAI時代」と謳う企業に入って何を感じているかを簡単にまとめました(本来はきちんとサーベイした後にまとめるべきでしたが…)。
このようにネットワークについて言及するのは、それが現実空間とサイバー空間を往き来するための架け橋となる技術だからです。私は「仕事を0にプライベートを100に」できるような世の中にしたいなと思っています。AIであろうと、他のコンピュータサイエンスの技術がどんなに発展しようと、あちらの世界へ触れるにはネットワークというものが必要不可欠です。内輪の話ですが、この会社に属する皆さんだからこそ、きちんとネットワーク・セキュリティに守られた上で新しいアプリケーションを生み出していけることに少しでも感謝していただけたらなと思います。
一応AI部ということで、こんな記事も書いていますのでよろしければご一読ください。 良いお年を。
日報から見えてくる新卒の成長と育成課題
1. Introduction
Junyaです。Qiitaに投稿しようとしましたが、プログラミング話題でもないので、はてなを開設しました。 Qiitaでは大学3年の冬に投稿したネットワーク ソケットプログラミングの閲覧数、いいね数が思ったより増えていて嬉しい限りです(あの頃の記事雑だな…)。
2019年3月に大学院修士課程を修了し、4月から東京汐留にある某企業で勤め始めて8か月が経過しました。 現在の部署では、社内事業で扱うWebアプリケーションの開発を行っています。とても恵まれたチームでして、積極的な意見や自己研鑽活動を推奨して頂けてます。
そういった環境の中で、新卒日報というPJを与えられました。大企業がやっているようなフォーマットありの固い形式ではなく、「紙でもOK」「メールでもOK」「Webサイト作って提出でもOK」という自由な課題です。条件は自分が一日の中で出来た事や感じた事を綴ればよいだけです。
今回の記事では、
- 日報システムをどんな風に体系を仕上げたか
- 8ヶ月の日報を振り返って何が見えてくるか
を中心に伝えられればなと思います。
注1)日報本文の中には社内情報も入っています。記事に展開する文章や画像の中に一部マスクされたものがあります。ご了承ください。
注2)私自身は自然言語処理の初心者です。分析手法やデータの取り扱いが初心者なので、温かい目で見守りください。
2. System Architecture
結論から申し上げますと、全てGoogle Apps Script(以下、GAS)で完結しています。およそ1ヶ月で製作しました。
社内事情によるものです(DBや継続的に稼働するサーバを使うには色々と手続きがクソ面倒でして、社内で自由に利用可能なG Suiteサービスを使いました)。
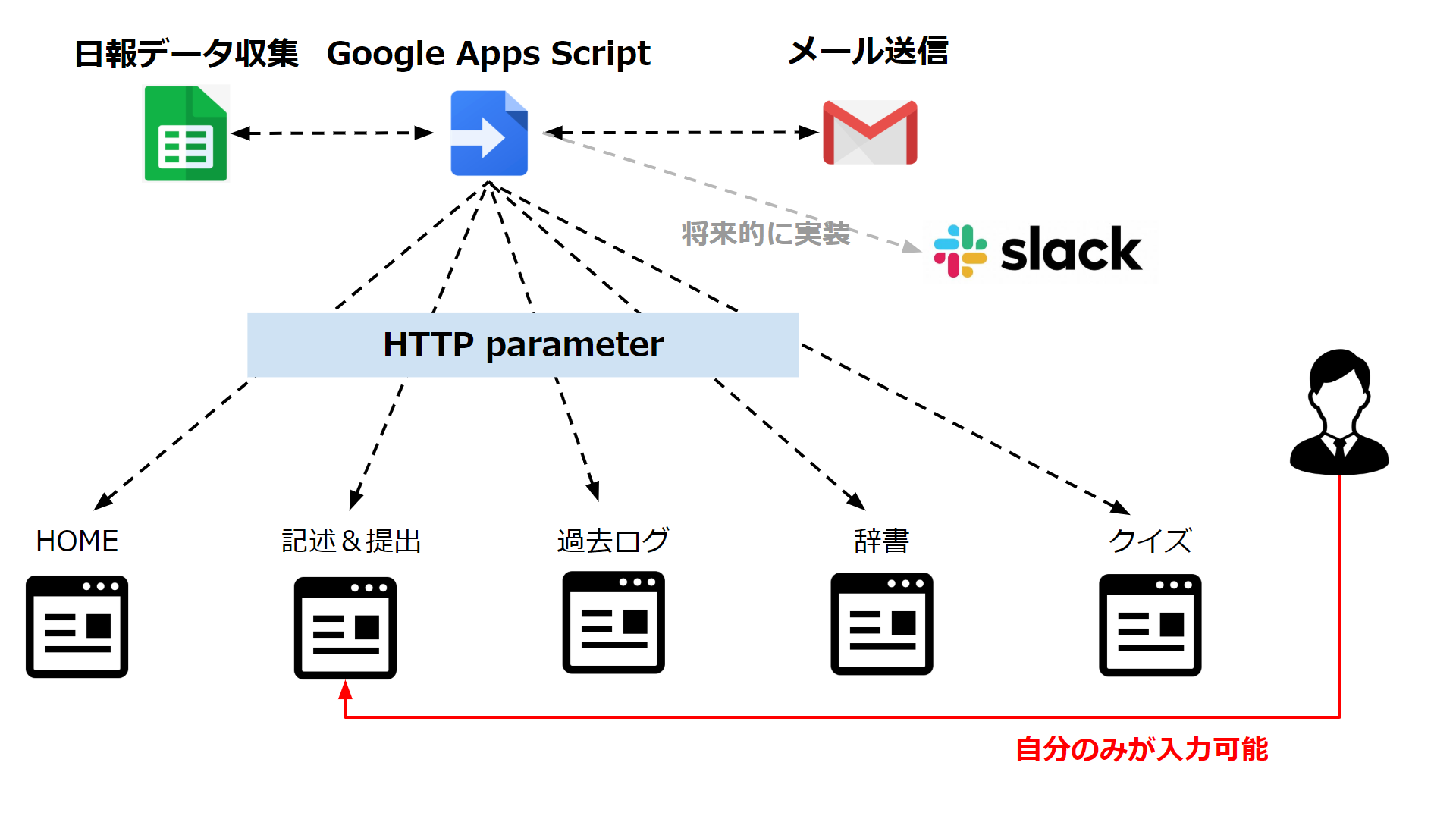
スプレッドシートをDB代わりに利用してます。I/Oは遅いですが、スクリプトの記述次第では影響ありません。 Sakaimo(@sakaimo)さんのスライドが参考になったりします。基本はGASのHTTPサービスを使って、Webサイト上で操作します。
- サイトアクセス(Google認証情報をスクリプトで取得)
- 各ページ遷移可能
- 日報記入ページへ遷移(スプレッドシート側でアクセスできるユーザを制限)
- 日報記述→下書きor提出
- メールにて上長、先輩へ送信
投稿した内容はHOMEページへ反映されます。記述内容や今日覚えたキーワードや業務内容を基にしたグラフを表示します。 残念ながらGASのコードは公開できませんが、ファイル相関図は以下のようになっています。拙いコンポーネント図ですが…。
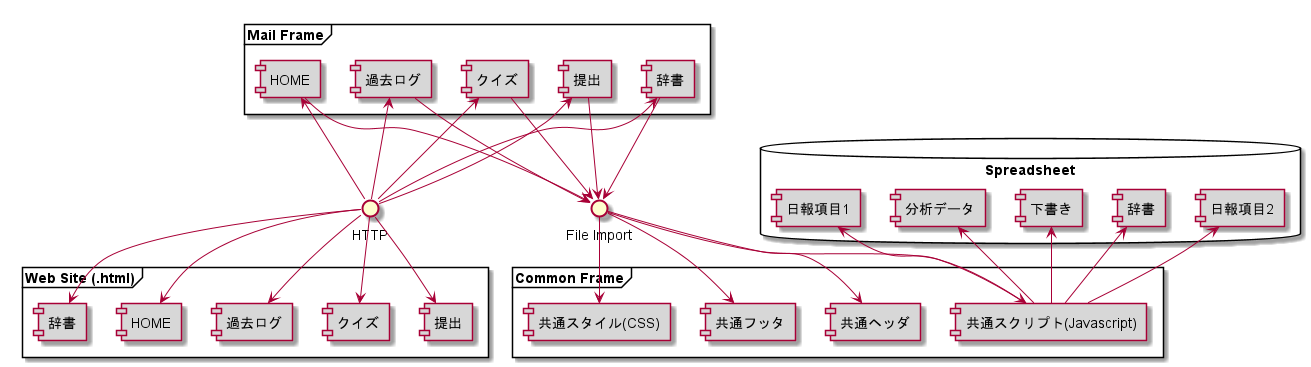
3. Report Analysis
企業には決算があります。普通、四半期というものに分けて各期で決算をしますね。特に、第1四半期と第2四半期を「上期」、第3四半期と第4四半期を「下期」と呼びます。企業によっては、上期の新卒社員を「試用期間」扱いしたりするそうです。
さて、10月に入り下期に突入したわけですが。いつまでも新人気分でいられるわけでもなく、上長とこんな議論をしました。 「今まで貯めた日報データ使って何かできないかな~」 おぉー、どこかで聞いたセリフ。ネットでよくある最近の企業の「AI使って何かやってよ~」に似てるぞ、おい。上期からそんな事を匂わせてはきましたが、遂に取り掛かることにしました。もちろん綺麗に成形されたデータではありません…。
3.1 Data Overview
私のチームには新卒がもう一人いるのですが、幸いにも日報の書き方が似通っていたので、2人分合わせて分析することとしました。まず初めに全体量を眺めてみました。土日祝除く、平日の日報投投稿数をプロットしました。ここで言う投稿数とは文の事です。日報スタイルとして、「~できました。」「~について取り組みました。」と一つ一つの出来事を羅列していく形になっています。これをカウントしました。なお、祝日の抜粋方法はPythonライブラリである jpholiday を用いています。
# jpholiday の使い方 # 2019.05.20 ~ 2019.11.22 の土日祝抜き日付リストを作成するコード例 import datetime as dt import jpholiday start = str(20190520) end = str(20191122) start_dt = dt.datetime.strptime(start, "%Y%m%d") end_dt = dt.datetime.strptime(end, "%Y%m%d") lst = [] t = start_dt while t <= end_dt: # is_holidayで日本の祝日か判定する if t.weekday() >= 5 or jpholiday.is_holiday(t.date()): t += dt.timedelta(days=1) continue lst.append(t.strftime('%Y/%m/%d')) t += dt.timedelta(days=1)
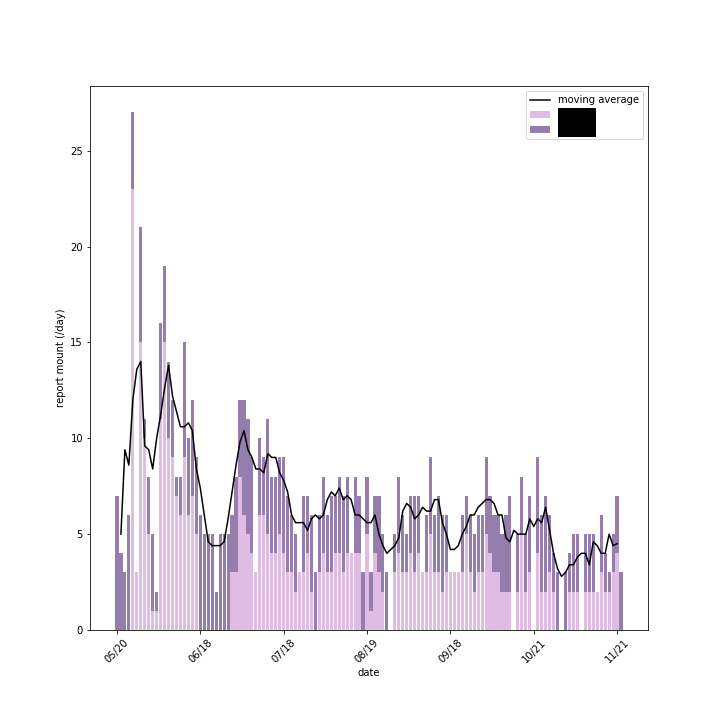
結果を積み上げ棒グラフにプロットしました。紫の濃淡は自分or同期を表してます。黒線は5日移動平均の値です。上期は一か月単位で周期性がありそうですね。これを見たときに真っ先に思い浮かびました。所属チームでは1ヶ月ごとにシステムリリースがあるということです!どんな形で、何を報告してもよいとう形になった結果、リリース前に日報書いている時間なんて存在しないことが伺えます(自虐)。
3.2 Sentence Analysis - Word Frequency
投稿数の上下は分かったところで、実際に普段どんなことを書いているのか、どんなことを書きがちかを分析しました。 今回はMeCabを使った形態素解析を基に、頻出単語や極性判定を行いました。
まずはMeCabで、全文章から名詞を抜き出してカウントしてみます。
import MeCab tagger = MeCab.Tagger("-Ochasen") tagger.parseToNode('ダミー') def extractKeyword(text): """Morphological analysis of text and returning a list of only nouns""" rep_text = str(text).replace('\\n', '') node = tagger.parseToNode(rep_text) keywords = [] while node: feature = node.feature.split(",")[0] if feature == u'名詞': # only noun keywords.append(str(node.surface)) node = node.next return keywords
まず私だけの結果を見てみます。同期のやつを晒すのもかわいそうなので。
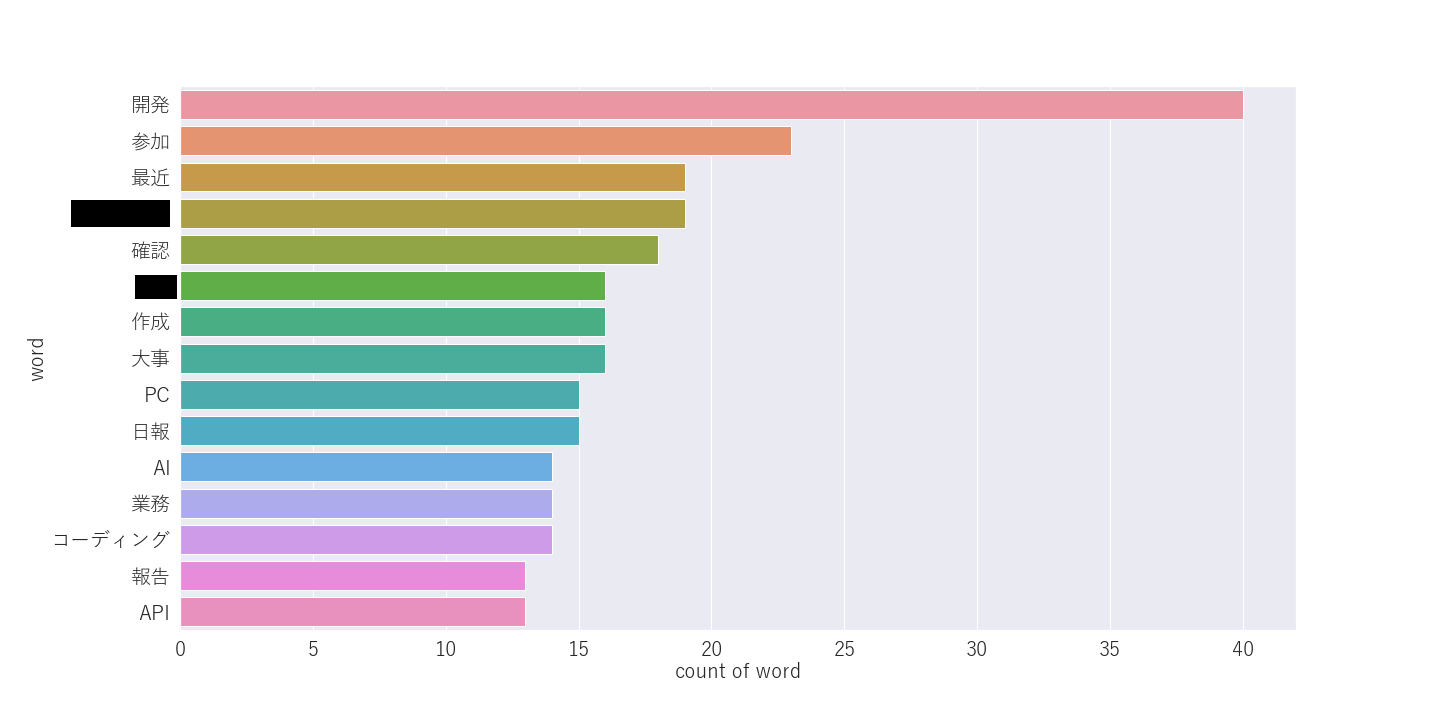
※冒頭にも述べましたが、一部ワードはマスクしています。
TOP15のワードについて考察します
- 「開発」「コーディング」「API」
- 確かにチームはフロア内で一番と言っていいほど自主開発に取り組んでいますので、コーディング量は圧倒的です。普段から開発の会話ばかり?
- 「参加」
- 新卒は様々なイベント行きますね。社内・社外問わず自由に行動させてもらい感謝してます。
- 「確認」「大事」「作成」「報告」
- 報連相を意識しているせいですかね?シンプルなビジネスの行動原則ですが大事さに毎日気づかされてます
- 「AI」
- となりの部署の若手先輩方とKaggleベースに機械学習勉強会やってますのいで、その話題も日報に書いてるためですね
同期と合わせるとこうなります。
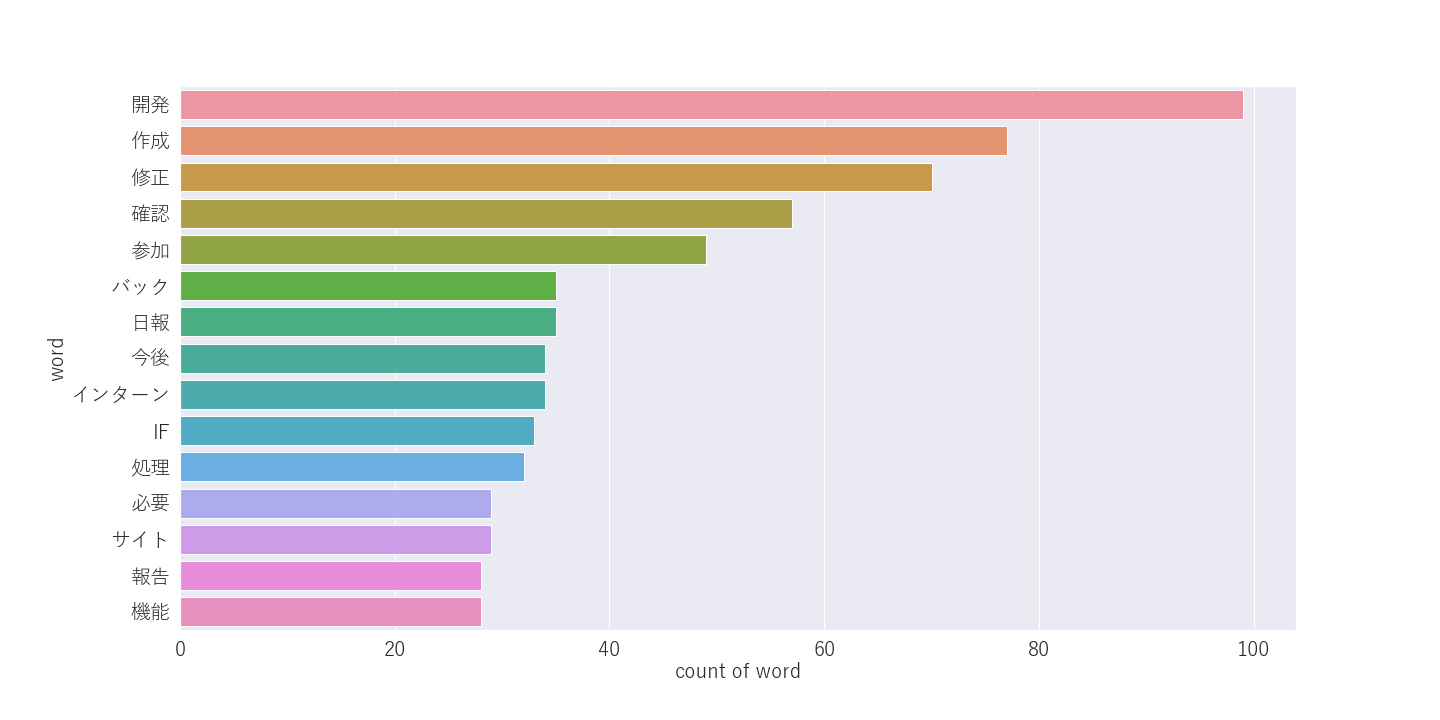
ほぼ同じです。バック=バックエンド開発の事です。バックだけ抜かれてるので、コーパスに存在しないのかと思われます。 2人とも「最近」「今後」という言葉が気になります。「最近何を思っているのか」「今後どうしていきたいのか、不安なのか」というニュアンスかもしれません。新卒がこのワードをいつ頃口にし始めるのかも気になるところです…(次回以降)。
3.3 Sentence Analysis - Polarity
ネガポジ判定と呼ばれる部類の分析です。一般的に単語には善し悪しのイメージがあります。「優しい」は善いイメージですし、「苛立つ」は悪いイメージですよね(あくまで一般的にです)。世の中にはそれをまとめた極性辞書なるものが存在して、単語ごとにスコア化されています。値域は ] です。今回は単純に、文章中の各単語のスコアを総和し、日ごとに和で集約しました。
今回用いた辞書は東工大の高村教授が作成したものとなります(参考ページ)
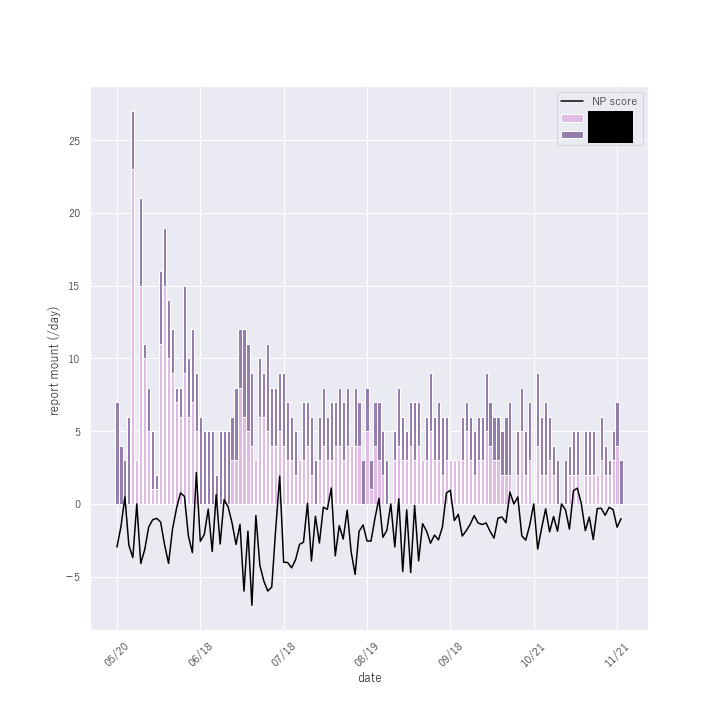
黒線が極性スコアのグラフです。棒グラフは3.1で導出した投稿数のプロットです。 見たところ0以上の(ポジティブが頻出する)日が少ないですね…。計算方法も雑ですので、これを見て一概に新卒社員は不満を感じています!とは言い切れないです。
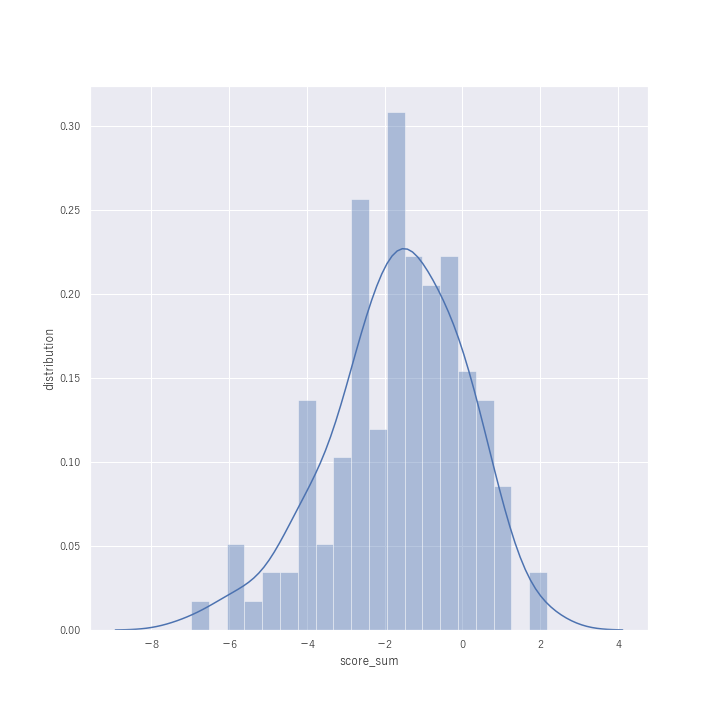
各日、各日報報告のスコアをヒストグラム化してみました。最頻値は あたりですね。

日報の中で、どんな動詞(発言や行動に結びつくと考えました)が善い悪いと捉えられているか、辞書のスコアをソートしてプロットしてみました。以下、考察です。
- 正のスコア
- 助ける → 普段から協調性高い証拠?
- 慣れる、励む、心掛ける → 一般的?
- 生きる → 頑張れ、新卒の俺。
- 負のスコア
- 早める、役立てる、進める
- 「早め早めに準備を」「何か役に立つものを」という言葉は新卒への過大なプレッシャーになったりするのかも
- 「〇〇の作業を進める」=「単調な日々になりつつある」という意味に捉えられなくはないです
- 早める、役立てる、進める
これらの結果を次のステップへ活かすのは難しそうですが、来年の新卒育成への材料になればよいと思っています。
4. Conclusion
今回は、とある企業の新卒が日報サイトを作製し、集めた日報を分析するという記事を書きました。 教訓は以下の3つです。
- 文章データの集め方は難しい。ある程度最初にどんな内容を書くかを具体化する必要がある?
- GASはもう嫌だ。
- 日報から成長度を測るのは難しいか。人材育成は定量化するのが難しそう。
あまり実装コードは記載できませんでしたが、成形した後GitHubにて公開したいと思います。